文章来源:夕小瑶科技说
夕小瑶科技说 原创
作者 | 付奶茶

最近几天,圈里讨论最热闹的、打开手机社媒平台给我推荐最凶的,就是WAIC 2024了,恨不得全国大大小小的AI厂商都跑去参加了,争奇斗艳,主打百花齐放,国内AI发展一片繁荣之态~
WAIC 2024 全称是2024世界人工智能大会暨人工智能全球治理高级别会议,在上海举办,论参会规模,它称得上国内AI大会的Top。
在大会圆桌会议上,行业大佬们谈论技术、应用、安全治理、发展等,分享自己对AI行业的深刻见解和前瞻性思考。

今天,谈谈这几天看到的一个非常有意思的话题:
开源大模型和闭源大模型究竟谁才是“智商税?
话题瞬间成为焦点!
自从ChatGPT推出以来,目前市场上有两种路径:开源和闭源。
闭源模型的代表OpenAI的ChatGPT及之后的模型、Anthropic的Claude系列,国内代表是百度的文心一言系列、智谱的部分GLM模型;
开源模型的代表则是Lecun带领的羊驼系列,从Llama 1逐步发展到最新的Llama 3,效果显著提升,并获得了广泛认可;国内的有面壁智能的MiniCPM、智谱GLM-130B等,截止到今年上半年,部分开源模型的能力已逼近甚至超越了GPT-4~

在这次讨论中,开源和闭源这个问题究竟谁是智商税竟然同时引起了两位大佬的青睐!奶茶给大家搬运过来,让我们听听行业大佬们的看法~
开源模型是一种‘智商税’?
7月4日在WAIC 2024期间,百度的创始人、董事长兼首席执行官李彦宏与第一财经传媒集团总编辑杨宇东及《硅谷 101》创始人陈茜进行了一次圆桌访谈,谈到了 “开源模型其实是一种智商税”。

李彦宏表示:“理性地分析大模型的价值及成本,你会发现闭源模型始终是最佳选择。无论是ChatGPT还是文心一言等闭源模型,其性能都优于开源模型,推理成本更低。”
他进一步解释道:“开源模型无法与闭源模型竞争。闭源模型有许多变种,可以根据用户需求选择最合适的模型,这些小规模的闭源模型往往比同规模的开源模型效果更好。”
李彦宏提出了几个独特观点:
通过在Transformer架构上增加技术,如RAG,几乎可以消除幻觉问题。
闭源模型的推理成本几乎可以忽略不计,尤其在国内,百度的轻量级模型都是免费的。
开源模型是一种智商税,因为闭源模型明明性能更强,推理成本更低。
早在今年4月李彦宏在内部讲话中就曾明确表示,开源大模型意义不大,闭源模型在能力上会持续领先。开闭源模型之争只是国内声势浩荡的“百模大战”带来的一个小争议。

李彦宏还谈到,过去一年多时间里,行业深陷“卷模型”的热潮,众多企业投入大量资源开发各类模型,虽然推动了国产大模型的进步,但也造成了社会资源的浪费,尤其是算力资源。
嗯?。。。
此外,他认为很多人混淆了模型开源和代码开源的概念:
“在相同参数规模的情况下,开源模型的能力往往不如闭源模型。若开源模型想要追平闭源模型的能力,就需要更大的参数规模,这必然导致推理成本增加和反应速度减缓。开源模型在学术研究、教学等特定场景下有其意义和价值,但在大多数应用场景中,商业化的闭源模型因其更高效、更精准的性能而更具优势。”
奶茶觉得李彦宏老师说的很有道理,但是也有一点不是非常认同~从现在的发展来看,确实闭源模型领先不少,可是从长远的人工智能发展、科技的发展来看,仅关注闭源模型当前时间节点的领先优势是不是有点早呢?
人工智能代表着未来,应该成为全人类的财富,开源能让每个人都有机会参与塑造这个未来,开源模型将大大提高模型的透明度和可解释性。尤其是,现在大模型的黑盒特性引发了诸多伦理争议,比如偏见、隐私泄露等。开源绝对是大大有利于社会各界审视模型,推动人工智能健康发展的~
闭源模型才是一种“智商税”?
而就在短短两天后,猎豹移动董事长兼CEO、猎户星空董事长傅盛也在这个问题上发表了自己的看法,和李彦宏的看法截然不同--开源和闭源模型是相互竞争、共同发展的关系,不应一方压倒另一方,但是付费的闭源大模型才是“智商税”:

“我并不完全地倾向于开源阵营。我的观点是开源和闭源这两个阵营是彼此共同竞争,共同发展,但是从某种意义上来说,闭源是比开源会好一点点,因为毕竟投那么多钱那么多人。但是,开源在很多时候也够用,发展也很快。所以,我判断他们之间不会产生那种所谓的一个遥遥在上,另一方发展不起来的局面。而且,AI的历史也表明,开源生态不是今天才出现的,在以前在语音转文字等识别技术上,开源的力量也非常强了。即便模型不是代码开源,依然是“众人拾柴火焰高”。它能够让更多的人去使用更多的科研院校、更多中小公司的开源模型产品,形成了一个巨大的反馈网络,所以我就说‘蚂蚁雄兵’,它产生力量也很大。”

傅盛还指出,开源、闭源模型都不是核心的问题,但是付费的闭源大模型是“智商税”:
“首先从逻辑上来说开源是智商税这就是错的,因为开源大模型是免费的,他怎么来的智商税呢,谁在收税?事实上,现在开源大模型各种性能已经挺好的,很多企业都在使用,他们也没向谁交钱。如果今天企业用付费闭源大模型,那才叫‘智商税’,尤其是收很高的模型授权费、API费用,一年花了数百上千万,最后买回去当个摆设,甚至员工根本用不起来(模型)。因此,真正要把大模型在企业用好,就得结合企业实际应用落地,无论选用什么样的模型,最终是把这个模型和企业的实际场景相结合,做强应用,这样企业才能真正把 AI 给用好。”
傅老师说的也有点道理!!
首先需要明确“智商税”这一概念。智商税通常指的是消费者因缺乏足够信息或知识而支付了高于实际价值的价格。
但是奶茶想,如果只谈成本的话,部署、使用开源大模型也并非完全免费啊,还是需要花费点钞能力的。

根据网友的验证,初次验证模型时,使用API调用是最划算的。如果要持续训练和处理大量数据,就需要使用自己的服务器和开源模型,这样成本可能会很高,但是直接说付费闭源大模型是“智商税”是否也也有些过于绝对了?【手动狗头】
小结
不久前,“AI教母”李飞飞所在的斯坦福以人为中心的人工智能研究所(HAI)2023 年全球人工智能发展趋势的报告,根据报告中数据统计显示,2023年新发布的人工智能模型中,有65.7% 是开源的,相比之下,2022年和2021年的比例分别为44.4%和33.3%,数量上的占比大幅上升。
在性能测试上,闭源模型通常优于开源模型,在10个选定的基准测试中,闭源模型的中值性能优势达到了24.2%,差异范围从数学任务的GSM8K的4.0%到代理任务的AgentBench的317.7%。
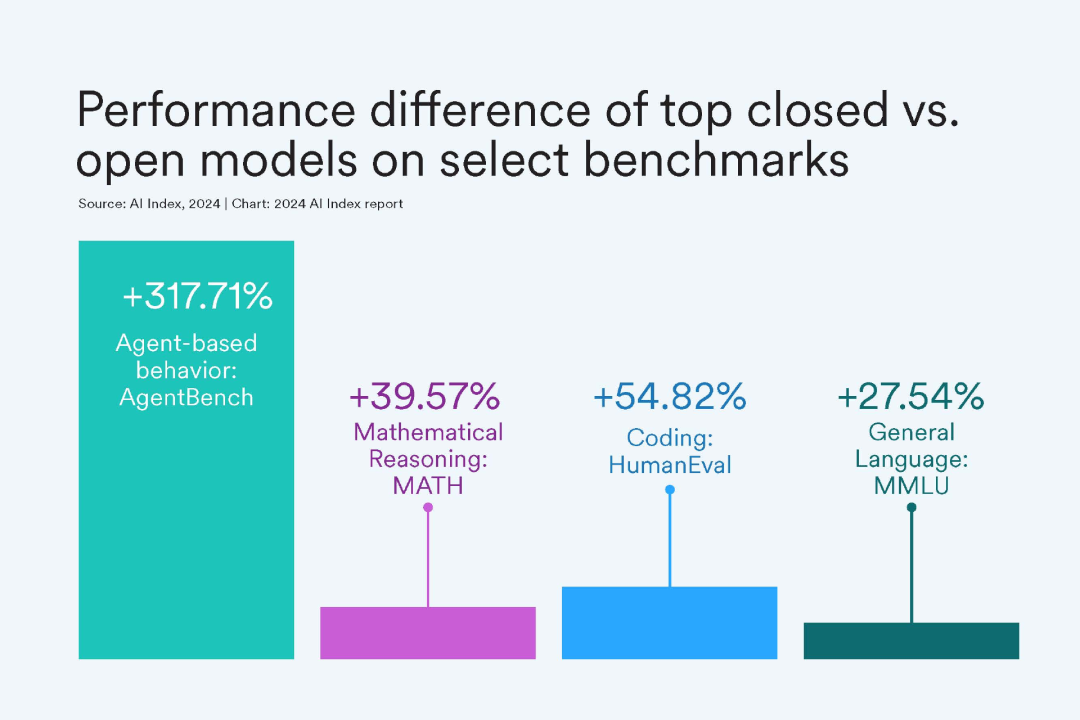
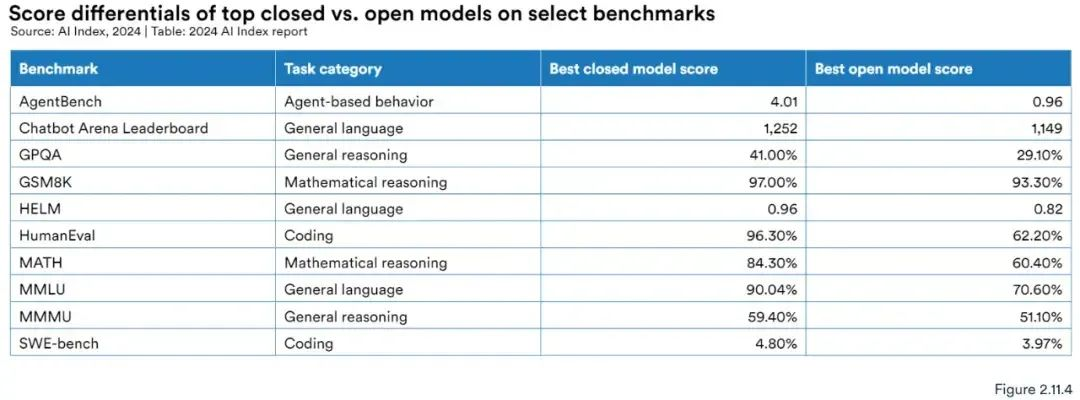
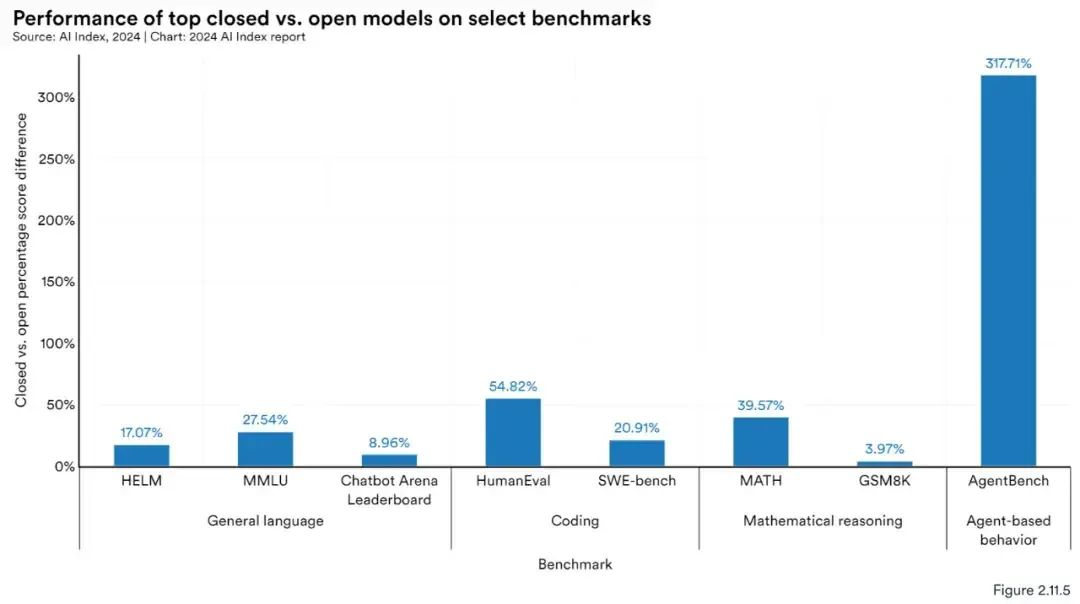
那开源、闭源究竟哪个好呢?(究竟谁不是智商税呢?)
奶茶是这样看的:
从成本的角度来看,闭源模型的API成本较低,如果仅是调用的话,总价更低。但从长远来看,特别是在数据量大的情况下,自建开源模型成本低、灵活,性价比应该是更高的,究竟哪种AI模型成本低,要看根据实际情况选定,从而实现AI的长期效益。
从安全的角度来看,开源模型的虽然更快地促进技术的发展和创新,但是会导致技术被滥用,比如生成有害内容,或者被恶意训练,而闭源可以更好地控制技术的使用,防止滥用,保护商业利益。
从社区的长远发展来看,开源是有利于知识共享的,能让更多人参与改进模型,推动人工智能民主化,集众人之智,加速突破。而闭源会限制创新,形成垄断,阻碍技术进步。奶茶认为,开源模型本质上和开源软件是一类问题。从软件发展的历史来看,开源已经被证明是一条成功之路,很多关键软件都是开源的,极大推动了产业进步。因为,即使开源完全可以采取一些保护措施,比如延迟开源、设置使用条款等,在促进创新和防止滥用之间取得平衡。
综上所述,奶茶认为,这个问题的答案是两者利弊共存。

无论什么样的工具,怎么“用”永远是关键,不能简单地追求某种模型的“开源”或“闭源”属性,开源与闭源之争不应被视为非此即彼的选择,而是AI生态系统中不可或缺的两个方面。未来的胜者很可能不是选择了开源或闭源,而是能够灵活运用两种策略,在动态变化的环境中找到最佳平衡点的企业和开发者。
我们可以将AI模型视为一个价值阶梯。底层的基础模型适合开源,以推动整个行业的进步。而随着模型向更高层次、更专业化的方向发展,闭源策略可能更有利于保护知识产权和商业利益。

关于开源和闭源的问题,奶茶问了下Claude,得到了一个非常有意思的回答:(它输出的时候,奶茶已经怀疑自己,到底是我训AI还是AI训我呢?)
我们可以将大模型的开源与闭源问题比作"薛定谔的AI"。以下是如何将这两个概念联系起来的分析:
1.不确定性原理:
- 薛定谔的猫:在观测前,猫既是活的又是死的。
- 大模型:在公开前,模型既是开源的又是闭源的。
2.观测行为的影响:
-薛定谔的猫:打开盒子的行为决定了猫的状态。
- 大模型:公司的决策行为决定了模型的开放状态.
3.叠加态:
- 薛定谔的猫:活猫和死猫的叠加态。
- 大模型:开源带来的创新潜力和闭源带来的商业利益的叠加态。
4.塌缩效应:
- 薛定谔的猫:观测导致量子态塌缩。
- 大模型:公司决策导致开源/闭源状态确定。
5.悖论:
- 薛定谔的猫:挑战了经典物理学的认知。
- 大模型:挑战了传统软件开发和商业模式。
6.影响因素:
- 薛定谔的猫:放射性原子衰变。
- 大模型:市场竞争、技术进步、伦理考虑等。
7.观测者效应:
- 薛定谔的猫:观测者影响实验结果。
- 大模型:公众期待和舆论压力影响公司决策。
本文链接:https://www.aixinzhijie.com/article/6846244
转载请注明文章出处
相关推荐

文章来源:真故研究室作者:江小玉 图片来源:由无界AI生成 当人们正在观望,AI什么时候抢走自己的饭碗时,北京一名9岁的小学生在AI的帮助下写了一本小说,并赚到了2万元的版税。...

来源:人民法院报,作者:华东政法大学教授杨凯虚拟货币司法处置的合规路径探索与优化,对于维护金融稳定、促进市场健康发展具有重要意义。我国应继续秉持审慎原则,通过出台全面的指导意见,为虚拟货币司法处置提供...

背景在上一期 Web3 安全入门避坑指南中,我们通过分析一些典型的空投骗局,讲解了用户在领取空投时可能面临的各种风险。近期,慢雾 AML 团队在分析受害者提交的 MistTrack ...





