随着高考的到来,数学考试再一次成为考生们心中的 “魔鬼”。在这场竞争中,六大人工智能模型也参与了挑战,分别是字节的豆包、腾讯的元宝、阿里的通义、百度的文心 X1Turbo、深度求索的 DeepSeek 以及 OpenAI 的 o3。此次测试采用的是2025年新课标 Ⅰ 卷的14道客观题,总分为73分,涵盖了单选题、多选题和填空题。
为了确保测试的公平性,所有模型在答题时都没有系统提示和联网搜索的支持,每个模型只能进行一次答题。经过一番较量,最终结果出乎意料,豆包和元宝同以68分的成绩并列第一,展现了出色的推理能力。相对而言,DeepSeek 和通义则稍显逊色,分别以63分和62分完赛。而文心 X1和 o3的表现则令人失望,尤其是 o3,仅获得34分,显现出对国内高考题目的适应性不足。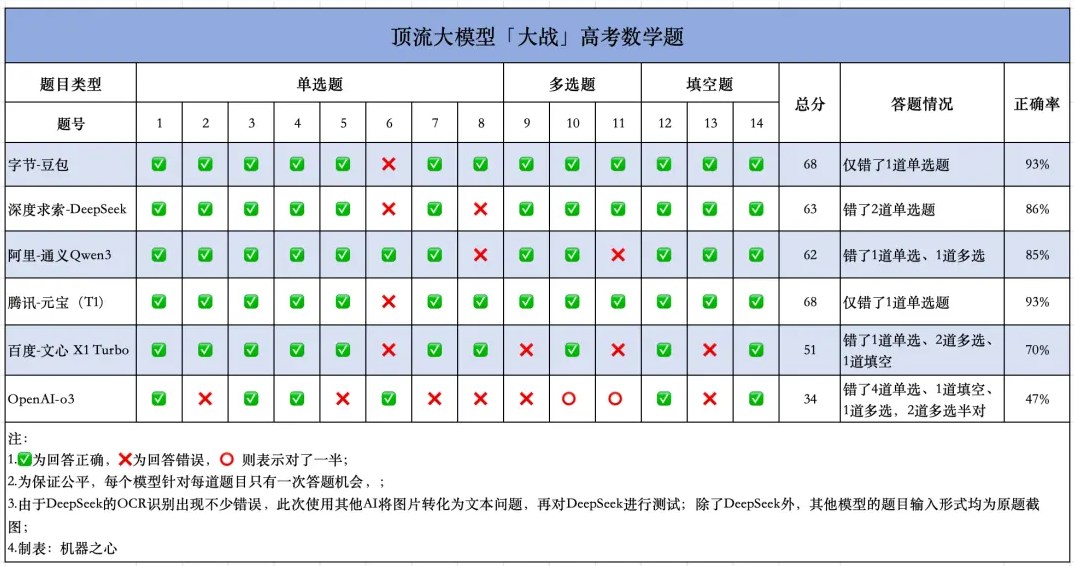 在具体题型的表现上,豆包、通义和元宝在单选题的表现颇为亮眼,各自得分35分。DeepSeek 因两道题失误拿下30分,而 o3则惨遭滑铁卢,单选题的得分仅为20分,错了一半的题目。而在多选题方面,豆包、DeepSeek 和元宝均表现完美,三道题全对,展现出强大的稳定性。相对来说,通义的表现虽然快速,但在关键时刻的判断失误也导致得分不理想。
此次测试不仅显示出各大 AI 模型在高考数学上的潜力和不足,也反映了它们在推理能力和反思能力上的进步。相较于去年,这些模型在细节处理、公式应用和逻辑推理上都有显著的提升。尽管仍然存在一些错误和不足,但这次比赛无疑为未来的 AI 数学能力打下了基础。https://www.aibase.com/zh/news/18739
在具体题型的表现上,豆包、通义和元宝在单选题的表现颇为亮眼,各自得分35分。DeepSeek 因两道题失误拿下30分,而 o3则惨遭滑铁卢,单选题的得分仅为20分,错了一半的题目。而在多选题方面,豆包、DeepSeek 和元宝均表现完美,三道题全对,展现出强大的稳定性。相对来说,通义的表现虽然快速,但在关键时刻的判断失误也导致得分不理想。
此次测试不仅显示出各大 AI 模型在高考数学上的潜力和不足,也反映了它们在推理能力和反思能力上的进步。相较于去年,这些模型在细节处理、公式应用和逻辑推理上都有显著的提升。尽管仍然存在一些错误和不足,但这次比赛无疑为未来的 AI 数学能力打下了基础。https://www.aibase.com/zh/news/18739







